
ArXiv
Preprint
Source Code
Github
Trained
Concept Sliders

Demo Colab:
Sliders Inference
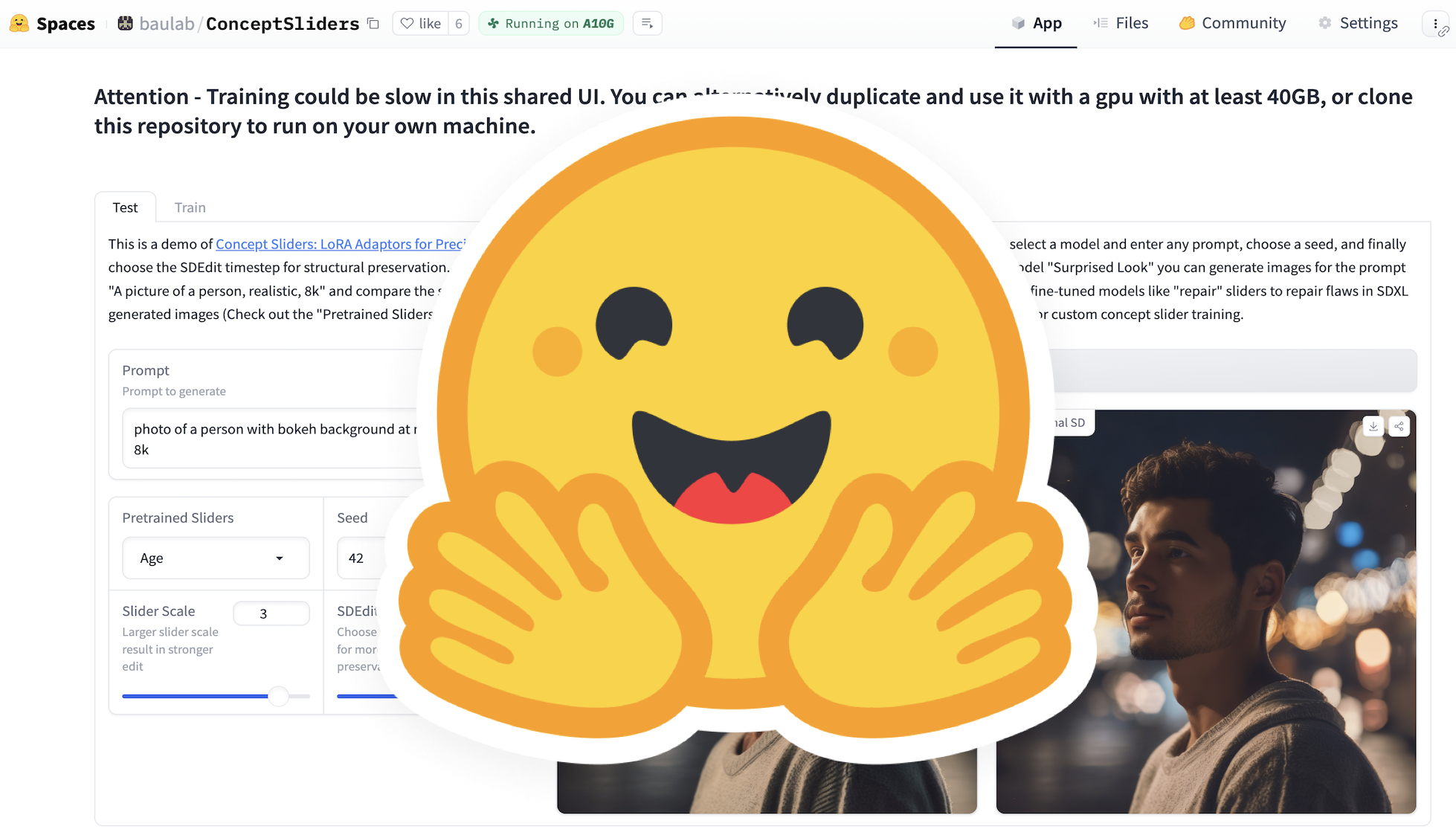
Huggingface
Demo
How to allow precise control of concepts in diffusion models?
Artists spend significant time crafting prompts and finding seeds to generate a desired image with text-to-image models. However, they need more nuanced, fine-grained control over attribute strengths like eye size or lighting in their generated images. Modifying the prompt disrupts overall structure. Artists require expressive control that maintains coherence.
To enable precise editing without changing structure, we present Concept Sliders that are plug-and-play low rank adaptors applied on top of pretrained models. By using simple text descriptions or a small set of paired images, we train concept sliders to represent the direction of desired attributes. At generation time, these sliders can be used to control the strength of the concept in the image, enabling nuanced tweaking.

Why allow concept control in diffusion models?
The ability to precisely modulate semantic concepts during image generation and editing unlocks new frontiers of creative expression for artists utilizing text-to-image diffusion models. As evidenced by recent discourse within artistic communities, limitations in concept control hinder creators' capacity to fully manifest their vision through these generative technologies. It is also expressed that sometimes these models generate blurry, distorted images
Modifying prompts tends to drastically alter image structure, making fine-tuned tweaks to match artistic preferences difficult. For example, an artist may spend hours crafting a prompt to generate a compelling scene, but lack ability to softly adjust lighter concepts like a subject's precise age or a storm's ambience to realize their creative goals. More intuitive, fine-grained control over textual and visual attributes would empower artists to tweak generations for nuanced refinement. In contrast, our Concept Sliders enables nuanced, continuous editing of visual attributes by identifying interpretable latent directions tied to specific concepts. By simply tuning the slider, artists gain finer-grained control over the generative process and can better shape outputs to match their artistic intentions.
How to control concepts in a model?
We propose two types of training - using text prompts alone and using image pairs. For concepts that are hard to describe in text or concepts that are not understood by the model, we propose using the image pair training. We first discuss training for Textual Concept Sliders.
Textual Concept Sliders
The idea is simple but powerful: the pretrained model Pθ*(x) has some pre-existing probability distribution to generate a concept t, so our goal is to learn some low-rank updates to the layers of the model, there by forming a new model Pθ(x) that reshapes its distribution by reducing the probability of an attribute c- and boost the probability of attribute c+ in an image when conditioned on t, according to the original pretrained model:
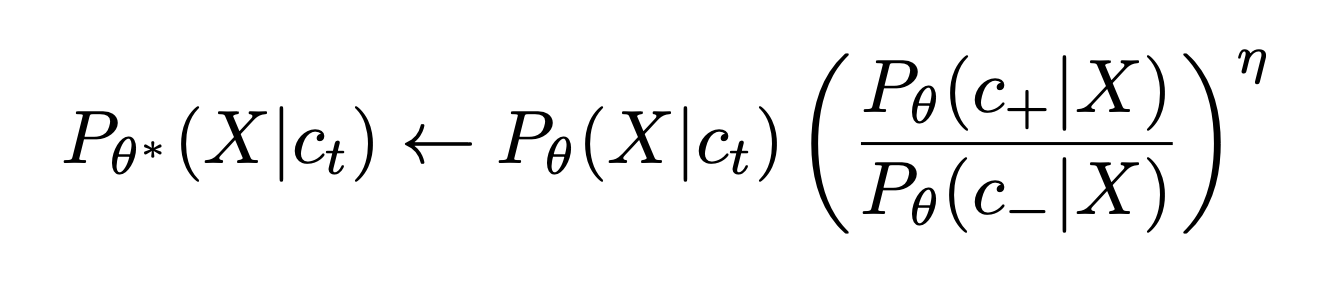
This is similar to the motivation behind compositional energy-based models. In diffusion it leads to a straightforward fine-tuning scheme that modifies the noise prediction model by subtracting a component and adding an component conditioned on the concept to target:
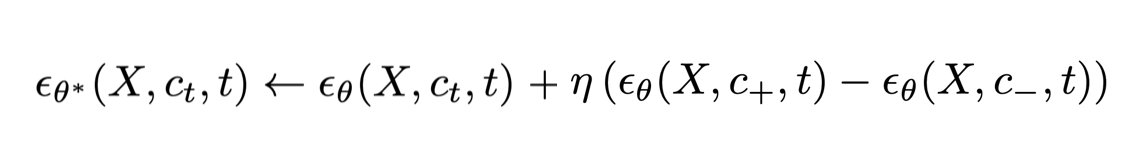
We query the frozen pre-trained model to predict the noise for the given target prompt, and control attribute prompts, then we train the edited model to guide it in the opposite direction using the ideas of classifier-free guidance at training time rather than inference. We find that fine-tuning the slider weights with this objective is very effective, producing a plug-and-play adaptor that directly controls the attributes for the target concept
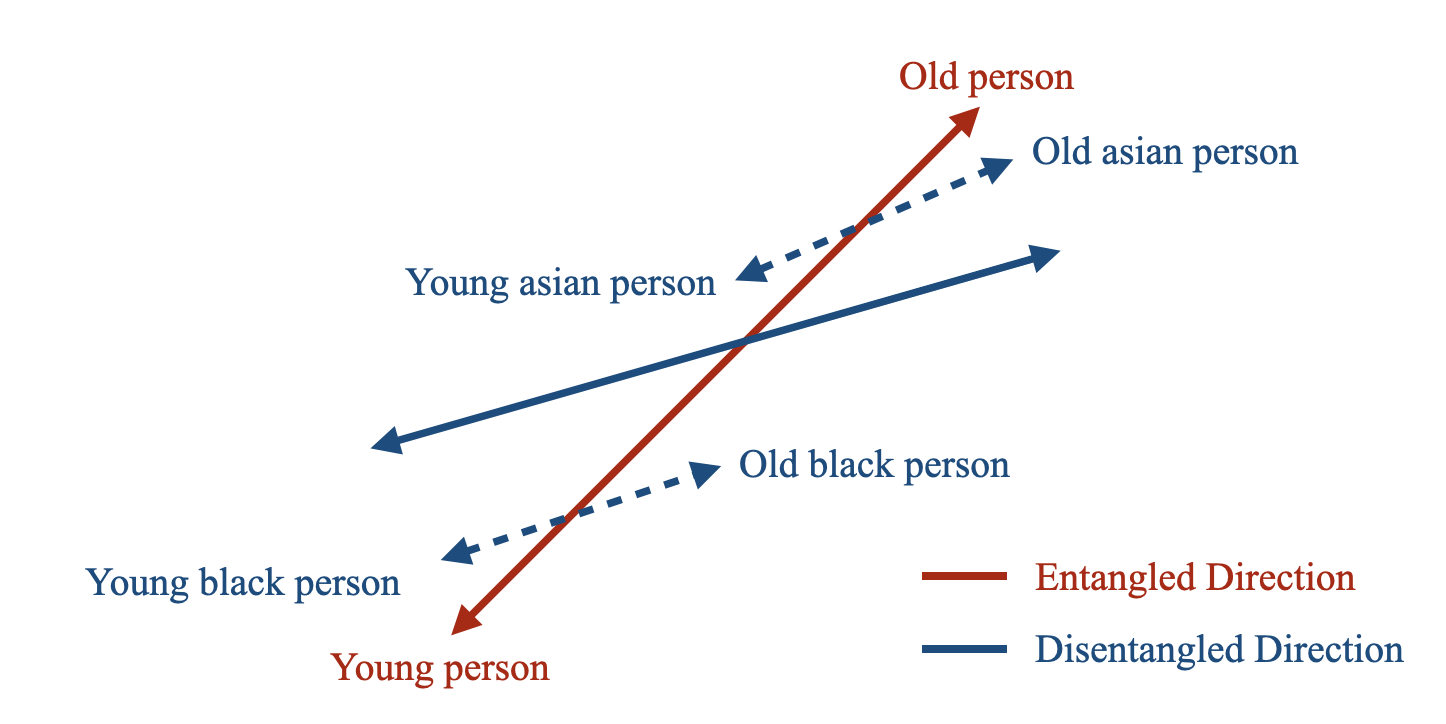
In practice, we notice that the concepts are entangled with each other. For instance, when we try to control the age attribute of a person, their race changes during inference. To avoid such undesired interference, we propose using a small set of preservation prompts to find the direction. Instead of defining the attribute with one pair of words alone, we define it by using multiple text compositions, finding a direction that changes the target attribute while holding other attribute-to-preserve constant.
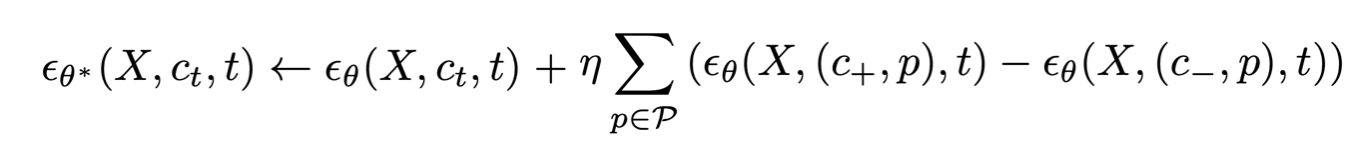
Visual Concept Sliders
To train sliders for concepts that can not be described with text prompts alone, we propose image pair based training. We particularly train the image based on gradient difference. The sliders learn to capture the visual concept through the contrast between image pairs (xA , xB ). Our training process optimizes the LORA applied in both the negative and positive directions. We shall write εθ+ for the application of positive LoRA and εθ- for the negative case. Then we minimize the following loss:
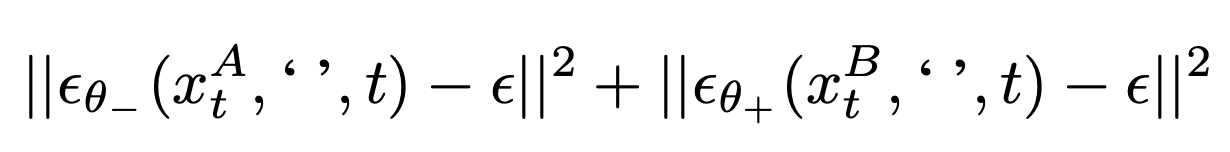
Why are Concept Sliders Low Rank and Disentangled?
We introduce low-rank constraints to our sliders for two main reasons. First, for efficiency in parameter count and computation. Second to precisely capture the edit direction with better generalization. The disentangled formulation helps isolating the edit from unwanted attributes. We show an ablation study to better understand the role of these two main components of our work.

Sliders to Improve Image Quality
One of the most interesting aspects of a large-scale generative model such as Stable Diffusion XL is that, although their image output can often suffer from distortions such as warped or blurry objects, the parameters of the model contains a latent capability to generate higher-quality output with fewer distortions than produced by default. Concept Sliders can unlock these abilities by identifying low-rank parameter directions that repair common distortions.



Controlling Textual Concepts
We study Textual Concept Sliders; our paper includes more quantitative analysis comparing previous image editing methods and text-based prompt editing methods.




Controlling Visual Concepts
Nunanced visual concepts can be controlled using our Visual Sliders; our paper shows comparisons with customization methods and some quantitative evaluations.

StyleGAN latents, especially the stylespace latents, can be transferred to Stable Diffusion. We collect images from styleGAN and train sliders on those images. We find that diffusion models can learn disentangled stylespace neuron behavior enabling artists to control nuanced attributes that are present in styleGAN.

Composing Multiple Sliders
A key advantage of our low-rank slider directions is composability - users can combine multiple sliders for nuanced control rather than being limited to one concept at a time. By downloading interesting slider sets, users can adjust multiple knobs simultaneously to steer complex generations


How to cite
The preprint can be cited as follows.
bibliography
Rohit Gandikota, Joanna Materzyńska, Tingrui Zhou, Antonio Torralba, David Bau. "Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models" in European Conference on Computer Vision (ECCV 2024).
bibtex
@inproceedings{gandikota2023sliders,
title={Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models},
author={Gandikota, Rohit and Materzy{\'n}ska, Joanna and Zhou, Tingrui and Torralba, Antonio and Bau, David},
booktitle={European Conference on Computer Vision},
year={2024},
note={arXiv:2311.12092}
}